
Podczas HPE Discover w Barcelonie gigant infrastruktury pokazał rozwiązanie, które ma szansę namieszać w strategiach największych dostawców chmury (CSP). HPE, we współpracy z AMD i Broadcomem, zaprezentowało architekturę „Helios”, kompletny system rack-scale, który nie tylko oferuje brutalną moc obliczeniową, ale przede wszystkim wprowadza otwarty standard Ethernet tam, gdzie dotychczas królowały zamknięte technologie.
W świecie infrastruktury pod AI trwa walka dwóch filozofii: zamkniętych, autorskich ekosystemów oraz otwartych standardów. HPE swoim najnowszym ruchem wyraźnie opowiada się za tą drugą opcją, celując w „neochmury” i gigantów hyperscale, którzy szukają wydajności bez przywiązania do jednego dostawcy na wieki.
HPE Helios – 72 “bestie” w jednej szafie
Sercem zaprezentowanej architektury jest potężna szafa serwerowa zbudowana zgodnie ze specyfikacją Open Compute Project (OCP). W jej wnętrzu upakowano aż 72 akceleratory AMD Instinct™ MI455X.
Liczby, jakimi chwali się HPE, robią wrażenie nawet na weteranach HPC:
- 2.9 Exaflops wydajności w precyzji FP4 dla najbardziej wymagających obliczeń AI.
- 31 TB pamięci HBM4 – to kluczowy parametr przy trenowaniu modeli o bilionach parametrów.
- 260 TB/s zagregowanej przepustowości scale-up.
- 1,4 petabajta/sekundę przepustowości pamięci
Parametry te umożliwiają trening modeli AI z bilionem parametrów oraz wysokowydajną inferencję w skali masowej, co dotychczas wymagało znacznie większej infrastruktury. Jednak takie zagęszczenie mocy wymaga specjalnego podejścia do termiki. System został zaprojektowany od podstaw z myślą o bezpośrednim chłodzeniu cieczą (DLC), co w przypadku tak gęstych instalacji staje się nie tyle opcją, co koniecznością inżynieryjną.
Ethernet wchodzi do gry w trybie Scale-Up
Największą innowacją „dla wtajemniczonych” jest jednak warstwa sieciowa. Dotychczas w komunikacji typu scale-up (czyli bezpośredniej, szybkiej wymianie danych między GPU w obrębie klastra) dominowały dedykowane, często własnościowe interkonekty jak np NVLink od NVIDII.
HPE, wykorzystując technologię przejętego Junipera oraz współpracę z Broadcomem, wprowadza tu standardowy Ethernet. System wykorzystuje chipy sieciowe Broadcom Tomahawk 6 oraz otwarty standard UALoE (Ultra Accelerator Link over Ethernet). Firma podkreśla, że to element większej strategii Networks for AI, obejmującej już rozwiązania scale-out i scale-across. Helios dopełnia tę układankę jako warstwa scale-up: serce trenowania modeli.
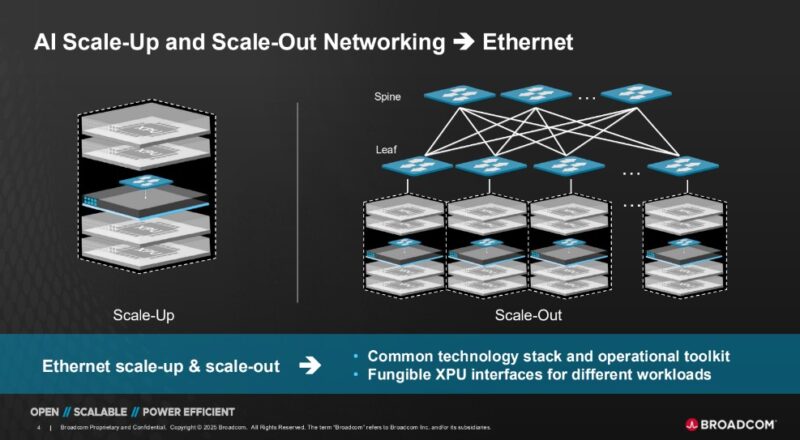
Co to oznacza w praktyce? HPE dostarcza pierwszy w branży przełącznik (switch) Ethernetowy typu scale-up, który jest w stanie obsłużyć gigantyczny ruch generowany przez trening AI, zachowując przy tym otwartość standardu. To strategiczny cios w technologie typu „walled garden”, dający klientom większą elastyczność i interoperacyjność.
Nasze wysokowydajne krzem dostarcza wiodące w branży ultraniskie opóźnienia, masową wydajność i bezstratną komunikację sieciową ze skalowalnością i efektywnością wymaganą przez nowoczesne obciążenia AI Hock E. Tan, prezes i CEO Broadcom.
Dostępność: Trzeba chwilę poczekać
Antonio Neri, CEO HPE, podkreśla, że celem jest zmniejszenie ryzyka i przyspieszenie wdrażania AI u klientów. Z kolei Dr. Lisa Su z AMD wskazuje, że Helios to efekt połączenia pełnego stosu technologicznego AMD z innowacjami systemowymi HPE.
Architektura jest imponująca, ale działy zakupów muszą uzbroić się w cierpliwość. HPE zapowiedziało globalną dostępność rozwiązania AMD „Helios” AI rack-scale na rok 2026. Do tego czasu walka o dominację w infrastrukturze AI z pewnością jeszcze przybierze na sile.