

Jeszcze niedawno uruchomienie dużego modelu językowego wymagało dostępu do chmury i mocnych serwerów. Dziś, wystarczy nawet dobry laptop z kartą RTX. Coraz więcej użytkowników decyduje się na lokalne środowiska AI, które zapewniają prywatność, pełną kontrolę nad danymi i brak kosztów subskrypcji. Jeśli masz komputer z Windows 11 i GPU od NVIDII, możesz dosłownie w kilka minut stworzyć własnego asystenta AI, korepetytora albo generator raportów działający offline.
AI lokalnie, bez chmury i abonamentu
Nowoczesne narzędzia, takie jak Ollama, AnythingLLM, LM Studio czy Project G-Assist, pozwalają na uruchamianie dużych modeli językowych (LLM) bezpośrednio na komputerze. To idealne rozwiązanie dla studentów, hobbystów AI czy programistów, którzy chcą eksperymentować z modelami bez wysyłania danych do chmury.
- Ollama to najprostszy sposób na rozpoczęcie pracy z lokalnymi modelami. Pozwala wczytywać pliki PDF, prowadzić rozmowy i testować projekty łączące tekst oraz obrazy.
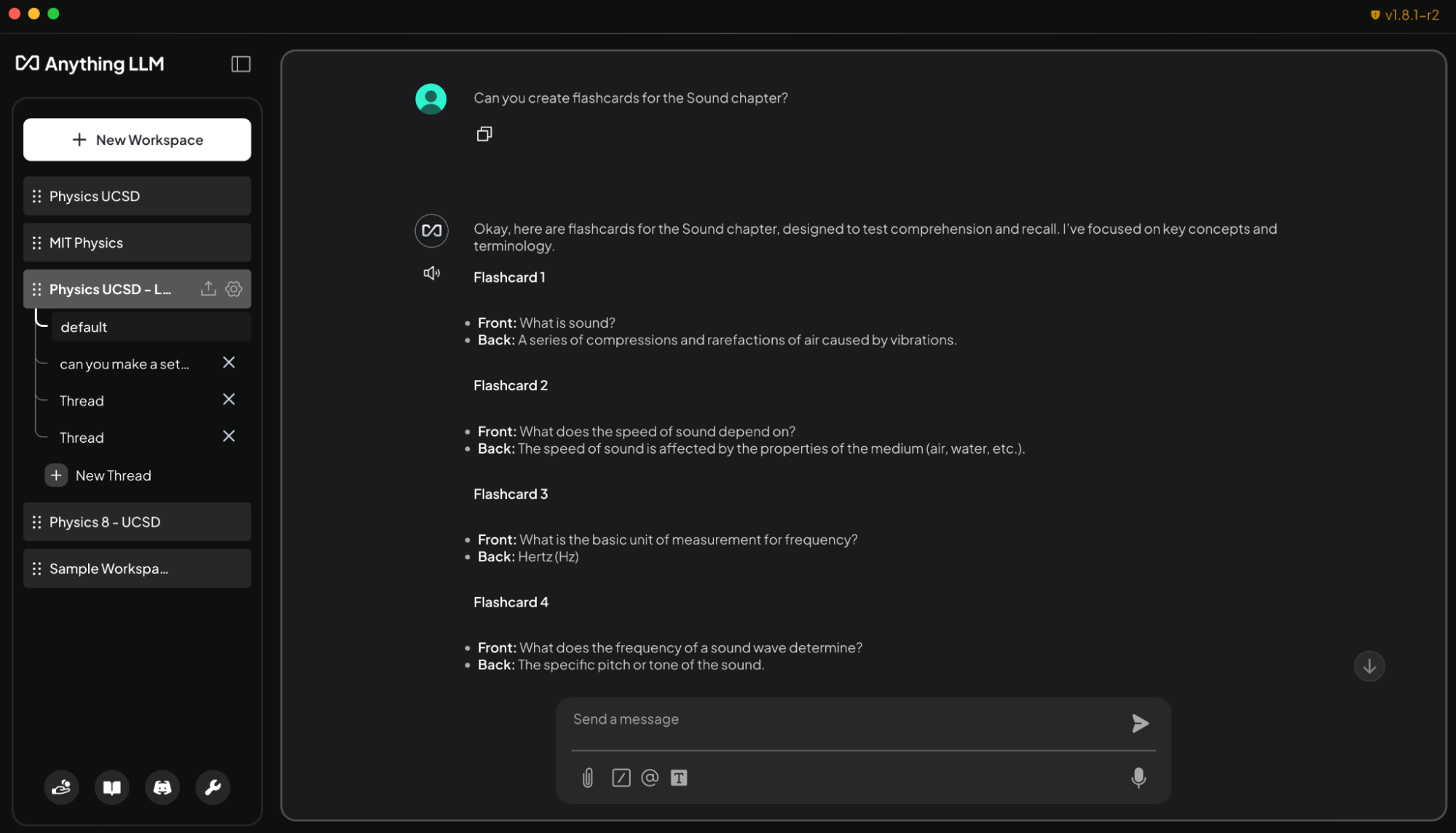
- AnythingLLM idzie krok dalej – pozwala stworzyć prywatnego asystenta AI, który generuje fiszki, quizy lub podsumowania na podstawie dokumentów.
- LM Studio, bazujące na frameworku llama.cpp, umożliwia łatwe testowanie różnych modeli i udostępnianie ich jako lokalnego API – idealne do integracji z własnymi aplikacjami.
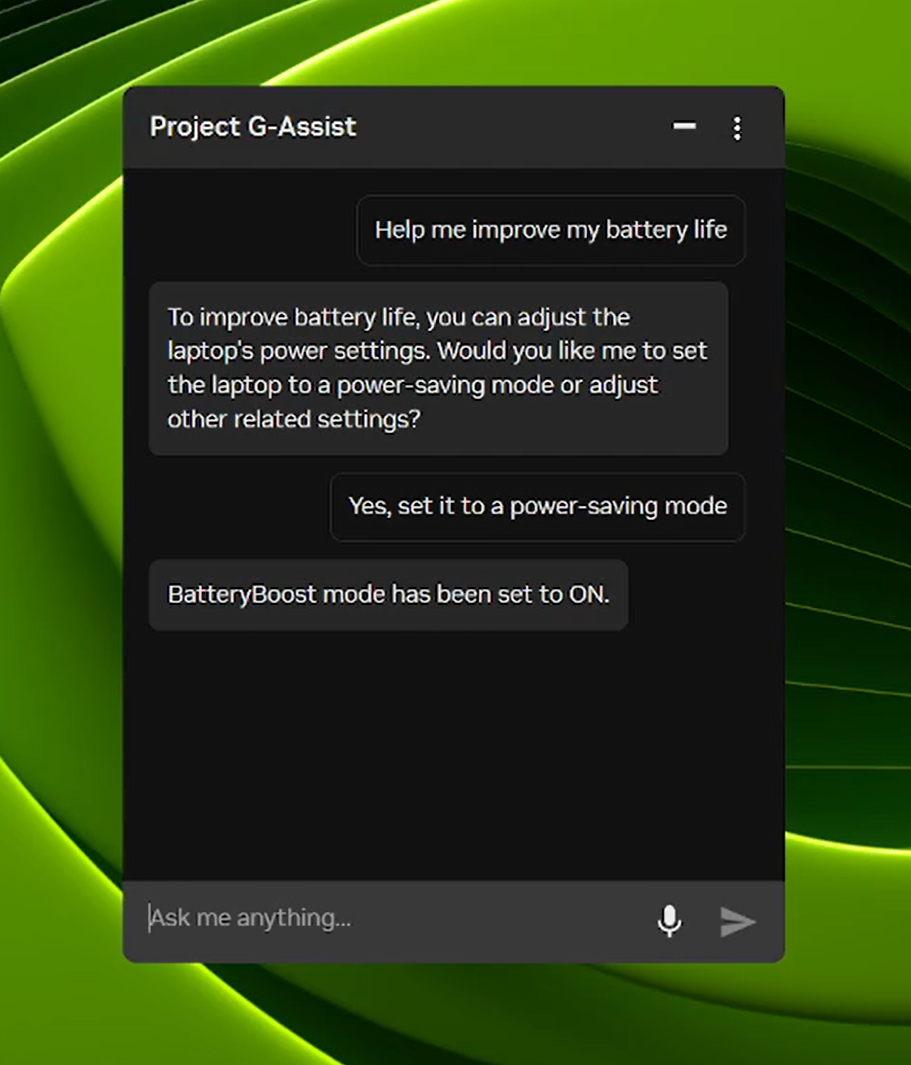
- Project G-Assist z kolei zamienia komputer w inteligentny system głosowy – użytkownik może sterować ustawieniami baterii, chłodzenia czy trybu wydajności za pomocą poleceń tekstowych lub głosowych.
Nowe możliwości dzięki kartom RTX
Najświeższe aktualizacje przynoszą znaczące przyspieszenia. Ollama zyskała nawet do 50% lepszą wydajność w modelach gpt-oss-20B i do 60% szybsze działanie modeli Gemma 3. Usprawniono również planowanie pamięci przy konfiguracjach wielogpu, co pozwala na jeszcze większe modele bez spowolnień.
Z kolei llama.cpp i GGML zostały zoptymalizowane pod kątem GPU RTX, z obsługą nowego modelu NVIDIA Nemotron Nano v2 9B oraz włączoną funkcją Flash Attention i ulepszonymi jądrami CUDA. Efekt? Płynniejsze działanie, mniejsze obciążenie pamięci i krótszy czas inferencji.
Microsoft również dokłada swoją cegiełkę. Najnowsze Windows ML z obsługą TensorRT potrafi przyspieszyć wnioskowanie o nawet 50%. Oznacza to, że modele językowe, dyfuzyjne czy predykcyjne działają teraz szybciej na standardowych laptopach z Windows 11 i GPU RTX.
AI Garage – baza wiedzy i praktyczne poradniki
Na blogu RTX AI Garage NVIDIA zebrała praktyczne wskazówki, jak rozpocząć pracę z lokalnymi modelami. Znajdziesz tam instrukcje instalacji Ollama, konfiguracji AnythingLLM oraz przykłady integracji modeli z własnymi projektami. To świetne miejsce dla każdego, kto chce spróbować AI bez wychodzenia poza swój komputer.